Базовый пример использования bosk#
В этом примере мы рассмотрим, как реализовать классический глубокий лес в рамках набора инструментов, реализованного в bosk.
[1]:
from bosk.pipeline.base import BasePipeline, Connection
from bosk.painter.graphviz import GraphvizPainter
from bosk.executor.recursive import RecursiveExecutor
from bosk.stages import Stage
from bosk.block.zoo.models.classification import RFCBlock, ETCBlock
from bosk.block.zoo.data_conversion import ConcatBlock, AverageBlock, ArgmaxBlock, StackBlock
from bosk.block.zoo.input_plugs import InputBlock, TargetInputBlock
from bosk.block.zoo.metrics import RocAucBlock
from bosk.pipeline.builder.functional import FunctionalPipelineBuilder
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
import numpy as np
from IPython.display import Image
[2]:
random_state = 42
n_estimators = 7
EXEC_CLS = RecursiveExecutor
def get_plain_dataset():
all_X, all_y = make_moons(noise=1, random_state=random_state)
train_X, test_X, train_y, test_y = train_test_split(
all_X, all_y, test_size=0.2, random_state=random_state)
return train_X, test_X, train_y, test_y
def draw_pipeline(pipeline: BasePipeline, rankdir: str = 'LR'):
GraphvizPainter(figure_dpi=100, figure_rankdir=rankdir).from_pipeline(pipeline).render('deep_forest.jpeg')
display(Image(filename='deep_forest.jpeg'))
Сперва мы будем использовать функциональный API для реализации классического глубокого леса с двумя слоями. Этот инструмент делает процесс создания соединений лаконичным. Мы просто создаем блоки и при их последующем вызове указываем, какие слоты блока мы хотим соединить с другими блоками. Название аргумента соответствует слоту, а значение указывает, какой блок мы хотим использовать в качестве входа для слота. Обратите внимание, что в этом примере все блоки имеют только один выходной слот, поэтому нам не нужно указывать, какой именно выходной слот использовать.
[3]:
# создание объекта, конструирующего конвейер
b = FunctionalPipelineBuilder()
# далее мы выполняем описанные выше действия
X, y = b.Input()(), b.TargetInput()()
rf_1 = b.RFC(n_estimators=n_estimators)(X=X, y=y)
et_1 = b.ETC(n_estimators=n_estimators)(X=X, y=y)
concat_1 = b.Concat(['X', 'rf_1', 'et_1'])(X=X, rf_1=rf_1, et_1=et_1)
rf_2 = b.RFC(n_estimators=n_estimators)(X=concat_1, y=y)
et_2 = b.ETC(n_estimators=n_estimators)(X=concat_1, y=y)
stack = b.Stack(['rf_2', 'et_2'], axis=1)(rf_2=rf_2, et_2=et_2)
average = b.Average(axis=1)(X=stack)
argmax = b.Argmax(axis=1)(X=average)
rf_1_roc_auc = b.RocAuc()(gt_y=y, pred_probas=rf_1)
roc_auc = b.RocAuc()(gt_y=y, pred_probas=average)
# создаем конвейер
pipeline = b.build(
{'X': X, 'y': y},
{'labels': argmax, 'probas': average, 'rf_1_roc-auc': rf_1_roc_auc, 'roc-auc': roc_auc}
)
pipeline.set_random_state(random_state)
# давайте изобразим наш конвейер
draw_pipeline(pipeline)

[4]:
# теперь давайте обучим и протестируем глубокий лес
# мы можем определить нужные входы и выходы
# в параметрах исполнителя
fit_executor = EXEC_CLS(
pipeline,
stage=Stage.FIT,
inputs=['X', 'y'],
outputs=['probas', 'rf_1_roc-auc', 'roc-auc']
)
transform_executor = EXEC_CLS(
pipeline,
stage=Stage.TRANSFORM,
inputs=['X'],
outputs=['probas', 'labels']
)
train_X, test_X, train_y, test_y = get_plain_dataset()
# Для запуска исполнителя нам нужно создать словарь,
# в котором ключами будут имена входов, а значениями данные.
# Результатом выполнения конвейера станет словарь с
# именами выходов в качестве ключей и BaseData в качестве значений,
# поэтому нам следует конвертировать BaseData в numpy массив
fit_result = fit_executor({'X': train_X, 'y': train_y}).numpy()
# Для обучения следующего слоя нам необходимо получить выход текущего,
# поэтому обучающий исполнитель на своем выходе должен дать преобразованные
# обучающие данные. Давайте проверим это
train_result = transform_executor({'X': train_X}).numpy()
print("Fit probas == probas on train:", np.allclose(fit_result['probas'], train_result['probas']))
Fit probas == probas on train: True
[5]:
# Теперь давайте посмотрим на метрики.
# Очевидно, что внешняя оценка должна совпадать
# с полученной в процессе обучения.
print("Train ROC-AUC:", roc_auc_score(train_y, train_result['probas'][:, 1]))
print(
"Train ROC-AUC calculated by fit executor:",
fit_result['roc-auc']
)
print(
"Train ROC-AUC for RF_1:",
fit_result['rf_1_roc-auc']
)
Train ROC-AUC: 1.0
Train ROC-AUC calculated by fit executor: 1.0
Train ROC-AUC for RF_1: 0.9892676767676768
[6]:
# И, наконец, мы можем поработать с тестовой выборкой
test_result = transform_executor({'X': test_X}).numpy()
print("Test ROC-AUC:", roc_auc_score(test_y, test_result['probas'][:, 1]))
Test ROC-AUC: 0.8571428571428572
Заметка о конвейерах#
Конвейер — это вычислительный граф в фреймворке bosk. В настоящее время наш фреймворк имеет только один тип конвейера: BasePipeline. BasePipeline — это класс данных, который содержит узлы графа (т. е. вычислительные блоки) и ребра (т. е. соединения). Поскольку вычислительный граф направлен и ацикличен, BasePipeline также содержит статическую информацию о входах и выходах (их имена и расположение). Несмотря на то, что нами не предусмотрена проверка на инъекцию, мы настоятельно
рекомендуем правильно помечать входы и выходы: разным слотам должны соответствовать разные имена.
Для маршрутизации данных по конвейеру была добавлена концепция слотов. Каждый блок имеет список входных и выходных слотов с уникальными (для данного блока) именами, куда могут направляться данные. Обычно выходной слот один, но это не обязательно. Таким образом, конвейер bosk может быть описан либо в терминах блоков, либо - слотов, так как каждый слот имеет ссылку на его родительский блок. Тем не менее, для построения конвейера вы должны работать только с точки зрения слотов и направлять данные из слота выходного блока во входной.
Заметка об исполнителях#
Исполнитель — это менеджер, который выполняет обработку вычислительного графа (то есть конвейера). Один конвейер может вести себя по-разному в зависимости от этапа вычислений. Например, чтобы соответствовать классической модели глубокого леса, нам нужно передать предикторы и отклики, но после процесса обучения нам нужно передать только новые предикторы. Для каждого из этих этапов пользователь должен создать отдельный исполнитель.
Конвейеры могут выполняться в последовательном или параллельном режиме (с точки зрения количества одновременно выполняемых вычислительных блоков; в обоих случаях для каждого блока может потребоваться несколько рабочих процессов). Мы рекомендуем запускать конвейеры в последовательном режиме, предоставляя как можно больше потоков каждому блоку, и использовать параллельное выполнение конвейера только в том случае, если у вас есть несколько устройств для обработки разных блоков (например, некоторые
блоки в конвейере выполняются на ЦПУ, а некоторые - на ГПУ). Для последовательного выполнения мы предлагаем использовать TopologicalExecutor, для параллельного – GreedyParallelExecutor. В этом примере мы будем использовать RecursiveExecutor, так как построенные конвейеры будут простыми.
Ручное создание конвейера#
Функциональный API — это удобный способ построения моделей в bosk. Однако, есть способ задать вычислительный граф вручную. Давайте реализуем тот же глубокий лес с помощью этой техники.
[7]:
# используем ручное соединение
# для начала нам нужно создать блоки для графа
# входные для факторов и откликов
input_x = InputBlock()
input_y = TargetInputBlock()
# несколько слоев глубокого леса со случайными лесами и
# сверхслучайными деревьями
rf_1 = RFCBlock(n_estimators=n_estimators)
et_1 = ETCBlock(n_estimators=n_estimators)
concat_1 = ConcatBlock(['rf_1', 'et_1', 'X'], axis=1)
rf_2 = RFCBlock(n_estimators=n_estimators)
et_2 = ETCBlock(n_estimators=n_estimators)
stack = StackBlock(['rf_2', 'et_2'], axis=1)
# блоки для вычисления результатов
average = AverageBlock(axis=1)
argmax = ArgmaxBlock(axis=1)
# и блоки-метрики
roc_auc = RocAucBlock()
roc_auc_rf_1 = RocAucBlock()
# нужно вручную задать наш конвейер: список блоков и соединений,
# входы и выходы
pipeline = BasePipeline(
nodes=[
input_x,
input_y,
rf_1,
et_1,
concat_1,
rf_2,
et_2,
stack,
average,
argmax,
roc_auc,
roc_auc_rf_1
],
connections=[
# вход X
Connection(input_x.slots.outputs['X'], rf_1.slots.inputs['X']),
Connection(input_x.slots.outputs['X'], et_1.slots.inputs['X']),
Connection(input_x.slots.outputs['X'], concat_1.slots.inputs['X']),
# вход y
Connection(input_y.slots.outputs['y'], rf_1.slots.inputs['y']),
Connection(input_y.slots.outputs['y'], et_1.slots.inputs['y']),
Connection(input_y.slots.outputs['y'], rf_2.slots.inputs['y']),
Connection(input_y.slots.outputs['y'], et_2.slots.inputs['y']),
# слои
Connection(rf_1.slots.outputs['output'], concat_1.slots.inputs['rf_1']),
Connection(et_1.slots.outputs['output'], concat_1.slots.inputs['et_1']),
Connection(concat_1.slots.outputs['output'], rf_2.slots.inputs['X']),
Connection(concat_1.slots.outputs['output'], et_2.slots.inputs['X']),
Connection(rf_2.slots.outputs['output'], stack.slots.inputs['rf_2']),
Connection(et_2.slots.outputs['output'], stack.slots.inputs['et_2']),
Connection(stack.slots.outputs['output'], average.slots.inputs['X']),
Connection(average.slots.outputs['output'], argmax.slots.inputs['X']),
Connection(average.slots.outputs['output'], roc_auc.slots.inputs['pred_probas']),
Connection(input_y.slots.outputs['y'], roc_auc.slots.inputs['gt_y']),
Connection(rf_1.slots.outputs['output'], roc_auc_rf_1.slots.inputs['pred_probas']),
Connection(input_y.slots.outputs['y'], roc_auc_rf_1.slots.inputs['gt_y']),
],
inputs={
'X': input_x.slots.inputs['X'],
'y': input_y.slots.inputs['y'],
},
outputs={
'probas': average.slots.outputs['output'],
'rf_1_roc-auc': roc_auc_rf_1.slots.outputs['roc-auc'],
'roc-auc': roc_auc.slots.outputs['roc-auc'],
'labels': argmax.slots.outputs['output']
}
)
pipeline.set_random_state(random_state)
# давайте нарисуем конвейер и убедимся, что результат одинаков
GraphvizPainter(figure_dpi=100).from_pipeline(pipeline).render('deep_forest.jpeg')
display(Image(filename='deep_forest.jpeg'))
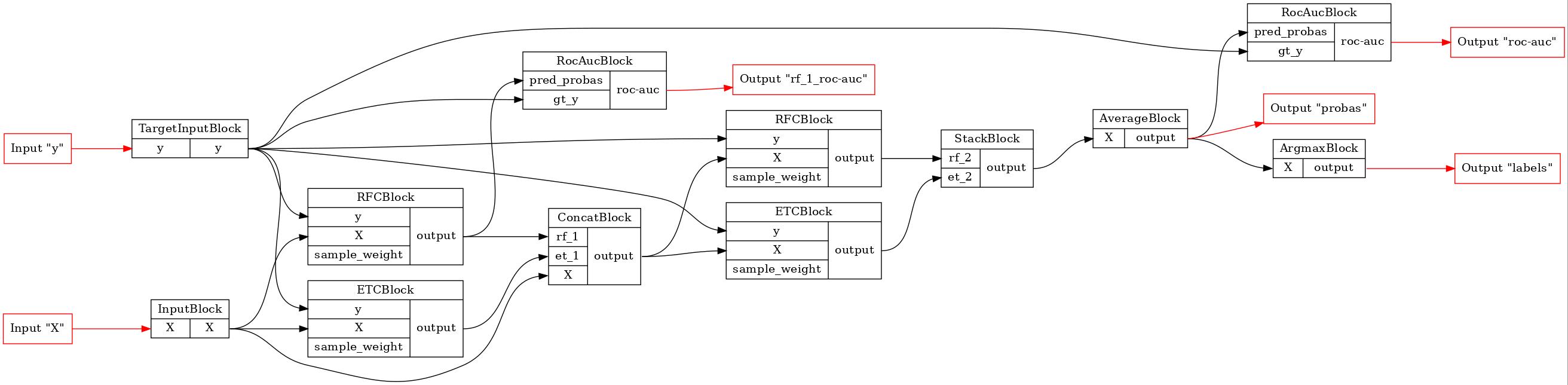
[8]:
# для завершения этого примера выполним те же тесты, что и выше
# и убедимся в том, что результаты одинаковы.
fit_executor = EXEC_CLS(
pipeline,
stage=Stage.FIT,
inputs=['X', 'y'],
outputs=['probas', 'rf_1_roc-auc', 'roc-auc']
)
transform_executor = EXEC_CLS(
pipeline,
stage=Stage.TRANSFORM,
inputs=['X'],
outputs=['probas', 'labels']
)
train_X, test_X, train_y, test_y = get_plain_dataset()
fit_result = fit_executor({'X': train_X, 'y': train_y}).numpy()
train_result = transform_executor({'X': train_X}).numpy()
print("Fit probas == probas on train:", np.allclose(fit_result['probas'], train_result['probas']))
print("Train ROC-AUC:", roc_auc_score(train_y, train_result['probas'][:, 1]))
print(
"Train ROC-AUC calculated by fit executor:",
fit_result['roc-auc']
)
print(
"Train ROC-AUC for RF_1:",
fit_result['rf_1_roc-auc']
)
test_result = transform_executor({'X': test_X}).numpy()
print("Test ROC-AUC:", roc_auc_score(test_y, test_result['probas'][:, 1]))
Fit probas == probas on train: True
Train ROC-AUC: 1.0
Train ROC-AUC calculated by fit executor: 1.0
Train ROC-AUC for RF_1: 0.9892676767676768
Test ROC-AUC: 0.8571428571428572