Инструкция по сериализации#
Иногда необходимо обучить модель на одном компьютере и использовать на другом. bosk предоставляет механизм сериализации для конвейеров и экземпляров блоков.
Заметка об условиях сериализации#
Конвейер является сериализуемым, если все блоки могут быть сериализованы. Если все значения поля __dict__ вашего блока сериализуемы, вам не нужно переопределять методы __setstate__ и __getstate__. Общую информацию о сериализации и этих методах можно найти здесь. Оболочка auto_block может автоматически создавать __setstate__ и __getstate__, если Вы передадите соответствующий аргумент.
Важно то, что если блок определяет метаинформацию слотов динамически, Вы должны использовать ZipPipelineSerializer, чтобы преодолеть трудности с десериализацией.
[1]:
from bosk.executor.topological import TopologicalExecutor
from bosk.painter.graphviz import GraphvizPainter
from bosk.pipeline.builder.functional import FunctionalPipelineBuilder
from bosk.pipeline.serializer.joblib import JoblibPipelineSerializer
from bosk.pipeline.serializer.zip import ZipPipelineSerializer
from bosk.pipeline.serializer.skops import SkopsBlockSerializer
from bosk.stages import Stage
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
import numpy as np
from IPython.display import Image
Определим следующий Глубокий лес:
[2]:
n_estimators = 17
b = FunctionalPipelineBuilder()
X, y = b.Input()(), b.TargetInput()()
rf_1 = b.RFC(n_estimators=n_estimators)(X=X, y=y)
et_1 = b.ETC(n_estimators=n_estimators)(X=X, y=y)
concat_1 = b.Concat(['X', 'rf_1', 'et_1'])(X=X, rf_1=rf_1, et_1=et_1)
rf_2 = b.RFC(n_estimators=n_estimators)(X=concat_1, y=y)
et_2 = b.ETC(n_estimators=n_estimators)(X=concat_1, y=y)
stack = b.Stack(['rf_2', 'et_2'], axis=1)(rf_2=rf_2, et_2=et_2)
average = b.Average(axis=1)(X=stack)
argmax = b.Argmax(axis=1)(X=average)
roc_auc = b.RocAuc()(gt_y=y, pred_probas=average)
pipeline = b.build(
{'X': X, 'y': y},
{'labels': argmax, 'probas': average, 'roc-auc': roc_auc}
)
GraphvizPainter(figure_dpi=100).from_pipeline(pipeline).render('pipeline.jpeg')
display(Image('pipeline.jpeg'))
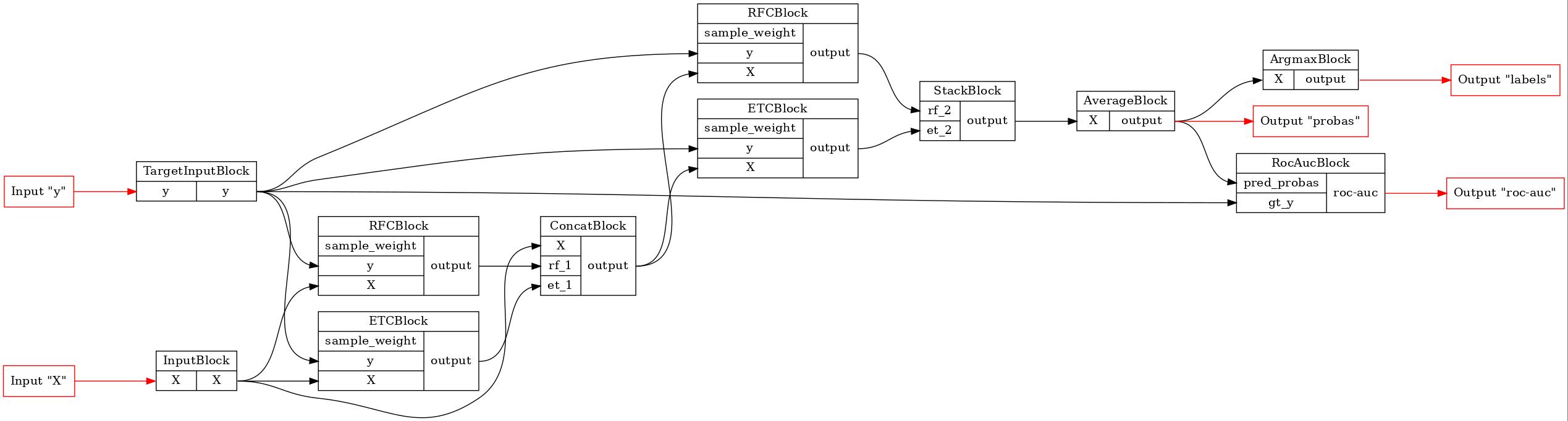
Сериализуем только что созданную модель и сравним результат десериализации с оригиналом. Мы будем использовать skops для сериализации блоков и сохраним пайплайн в zip-файл.
[3]:
zip_serial = ZipPipelineSerializer(SkopsBlockSerializer())
zip_serial.dump(pipeline, 'pipeline.zip')
pipeline = zip_serial.load('pipeline.zip')
GraphvizPainter(figure_dpi=100).from_pipeline(pipeline).render('pipeline.jpeg')
display(Image('pipeline.jpeg'))
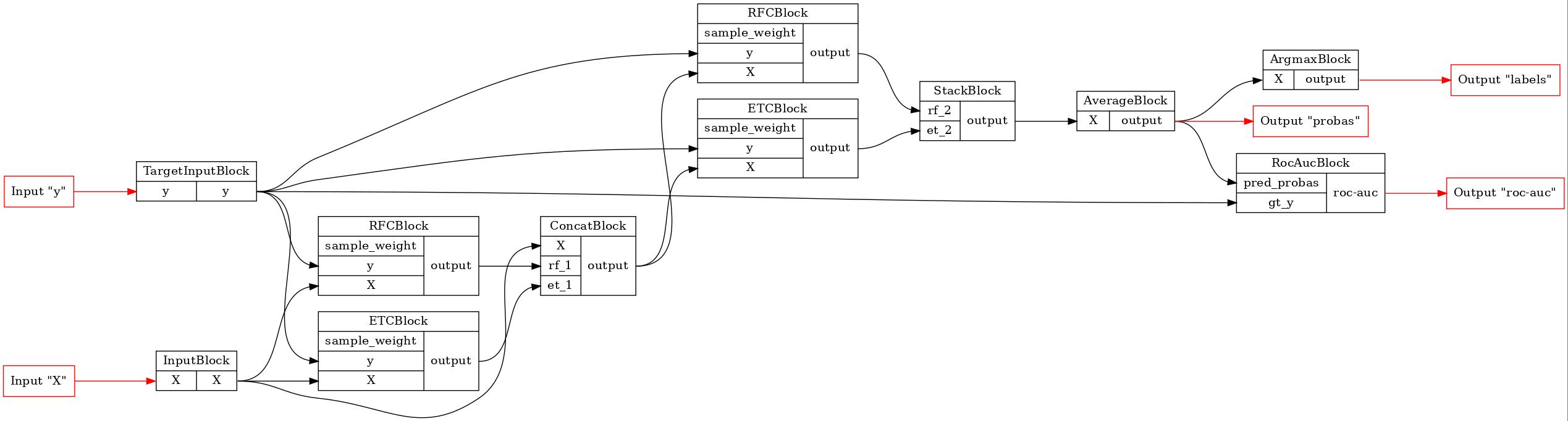
Как можно заметить, структура конвейера не изменилась.
Давайте обучим нашу модель и попробуем выполнить тест сериализации с обученным экземпляром. На этот раз мы будем использовать joblib.
[4]:
all_X, all_y = make_moons(100, noise=0.5)
train_X, test_X, train_y, _ = train_test_split(all_X, all_y, test_size=0.2)
train_data = {'X': train_X, 'y': train_y}
test_data = {'X': test_X}
fit_executor = TopologicalExecutor(
pipeline,
stage=Stage.FIT,
inputs=['X', 'y'],
outputs=['probas'],
)
fit_results = fit_executor(train_data)
joblib_serial = JoblibPipelineSerializer()
joblib_serial.dump(pipeline, 'pipeline.gz')
pipeline_copy = joblib_serial.load('pipeline.gz')
exec_1 = TopologicalExecutor(pipeline, Stage.TRANSFORM, inputs=['X'], outputs=['probas'])
exec_2 = TopologicalExecutor(pipeline_copy, Stage.TRANSFORM, inputs=['X'], outputs=['probas'])
res_1 = exec_1(test_data).numpy()
res_2 = exec_2(test_data).numpy()
print("L1 metric between the original and deserialized pipelines' probabilities:",
np.sum(np.abs(res_1['probas'] - res_2['probas'])))
L1 metric between the original and deserialized pipelines' probabilities: 0.0